【5000字保姆级教程】沉浸式历史故事视频Coze工作流智能体搭建教程

大家好,我是粒子不息、攀登不止的子峰。愿在算力洪流中,用自己跳动的算法脉冲,编译更多可能的轨迹。与同行者共赴山巅,一起训练未来 ,用AI点亮文明✨,用代码重构纪元

注意:本文5千多字!需要花一定时间阅读。
Ps:各个节点的提示词和代码我都打包成文档了,有需要找下子峰
最近看到祖国将要举行9.3阅兵的新闻,我是非常激动的,虽然我是95后,但读过近代史的都知道,我们受过多少屈辱,这一路走来是非常不易的,特别是现在世界动荡不安,我们有实力捍卫和平、伸张正义,此生无憾生于华夏!
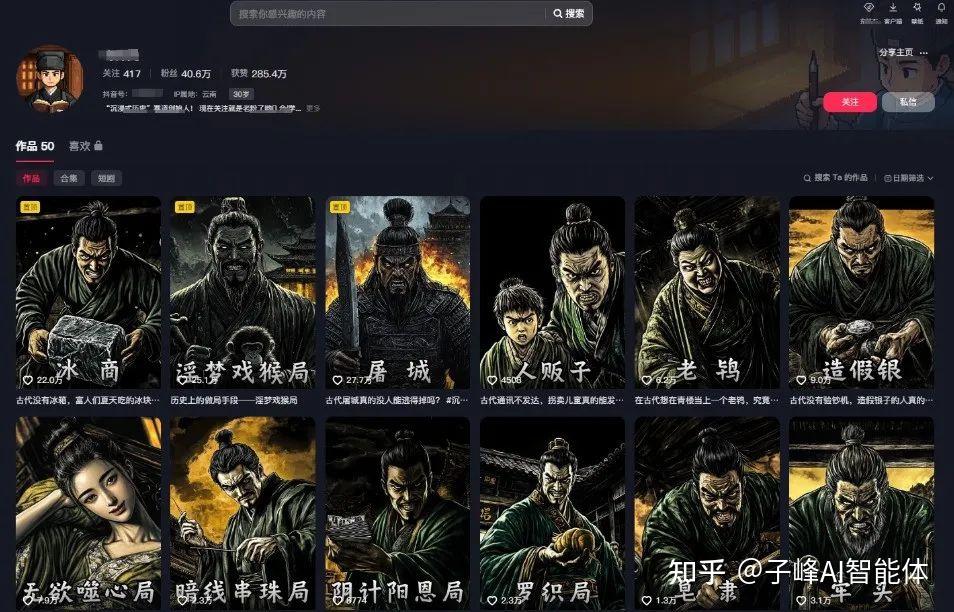
这几天,比我父母还都懂我,某短视频平台一直给我推送这种沉浸式历史故事视频,说实话,我从小学就开始收藏了看四大名著原文、玩小霸王历史游戏、追历史剧,当然也喜欢看抗战剧,最近就是想重温下,在短视频划拉划拉几下,就频繁给我推荐了,还好都是短视频,不然我大半天又要沉浸在历史故事的大海里。
自从移动互联网的兴起,越来越少人看书,越来越少人打开电视,而是,越来越多人泡在短视频,碎片化的娱乐更能吸引大家的注意力。
以前的什么书的内容,我现在已经忘的光光了,却能容易调取记忆里视频的某个画面,个人总结就是,短视频有简短省时、易懂印象深等优点。

我再看下刚刷到过的这类视频,点赞都是几千上万的,我发现,某个领域结合短视频都是一个不错的赛道,随着AI的时代来袭,AI又能进一步赋能,降本增效就是利用AI的必然使命,比如:以前我制作一条视频需要1个小时,现在利用AI之后所需时间是仅仅两分钟!
这不,这种历史故事视频被AI工作流解决了,我给出了三个你难以拒绝的优点:自动化、批量、省时省力。
生成效果:

工作流流程分析
整体的逻辑流程如下:
用户主题→生成文案→生成各种素材→素材数据组装处理→云端合成视频→输出视频草稿链接
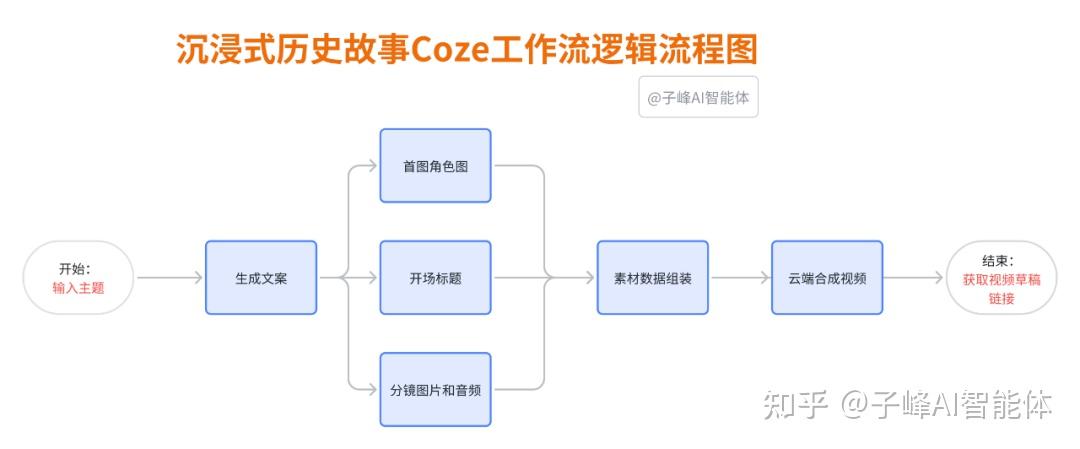
整体的 Coze工作流程如下:
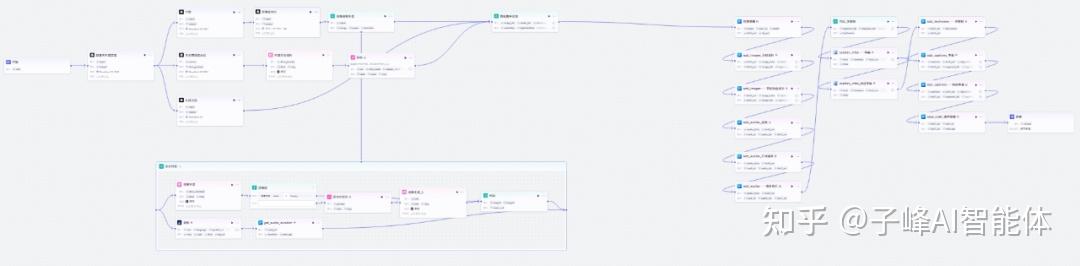
沉浸式历史故事Coze工作流搭建教程:
1.打开并登录Coze平台
浏览器搜索“Coze”,找到并登录访问http://coze.cn官网,在左上角点击【开发平台】,然后下方点击【快速开始】

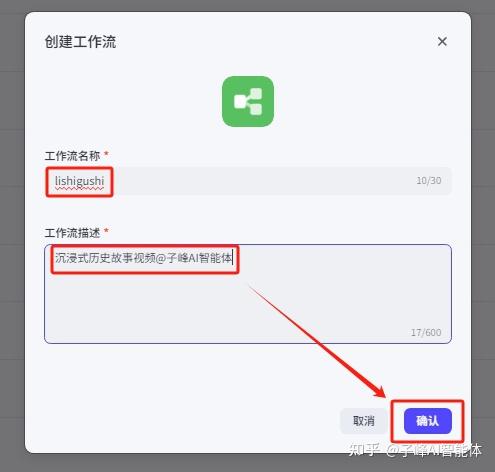
2.填写工作流的基本描述
在工作空间——资源库——资源库的右上角点击【资源】并创建工作流,填写这个Coze工作流的名称和描述(如图,名称必须用拼音或英文都),并点击【确认】创建
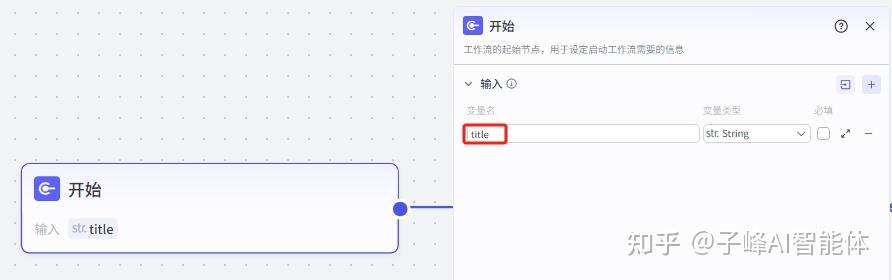
3.开始节点的设置
刚开始都是只有两个节点,一个开始节点和结束节点,我们先从开始节点开始搭建。
我们先把开始节点的变量名改一下,命名为:title
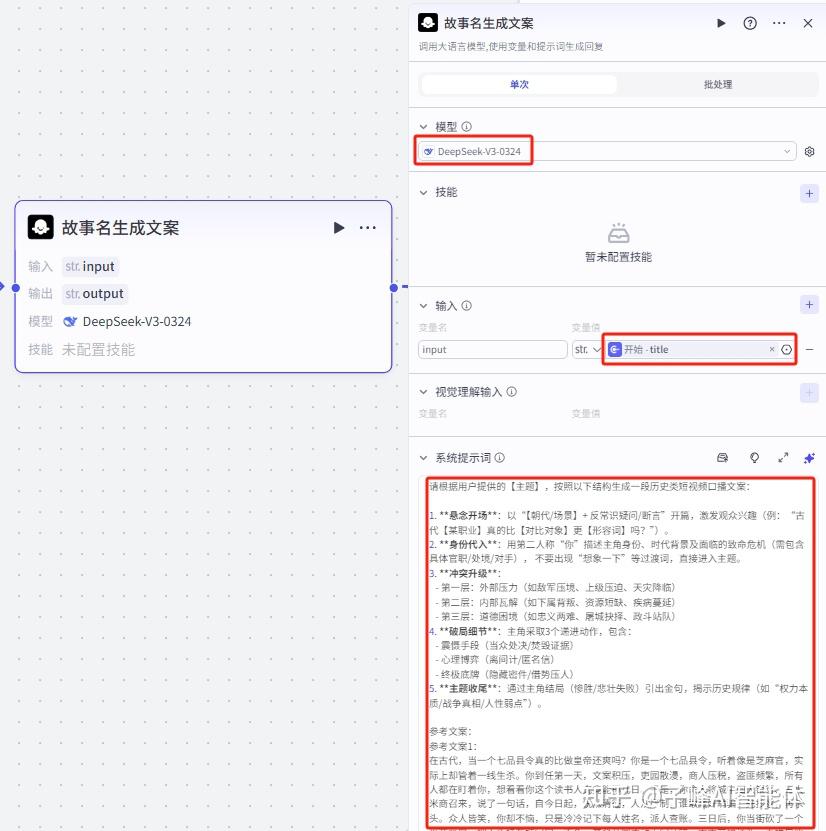
4.生成文案节点的配置
接下来添加一个大模型,他负责的是把开始节点输入的故事名称通过这个大模型的系统提示词来生成文案,模型这里找到并选择“Deepseek-V3”,输入变量值这里我们选择开始节点的“title”,在系统提示词这里,需要输入我们的文案提示词。
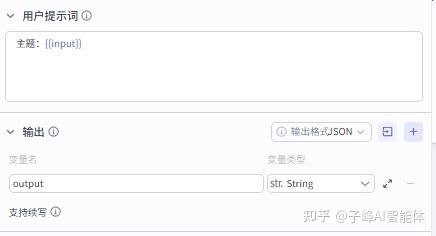
“用户提示词”这里向模型提供用户指令,先填上“主题:”,这里的主题要与系统提示词里的指令的主题要一致,然后我们按shift+括号键,把我们输入进来的变量给到大模型识别,这个变量变成蓝色就说明已经成功了。
5.开场角色图片的生成
下一步需要生成我们主角的首图,需要用到这三个节点来完成。
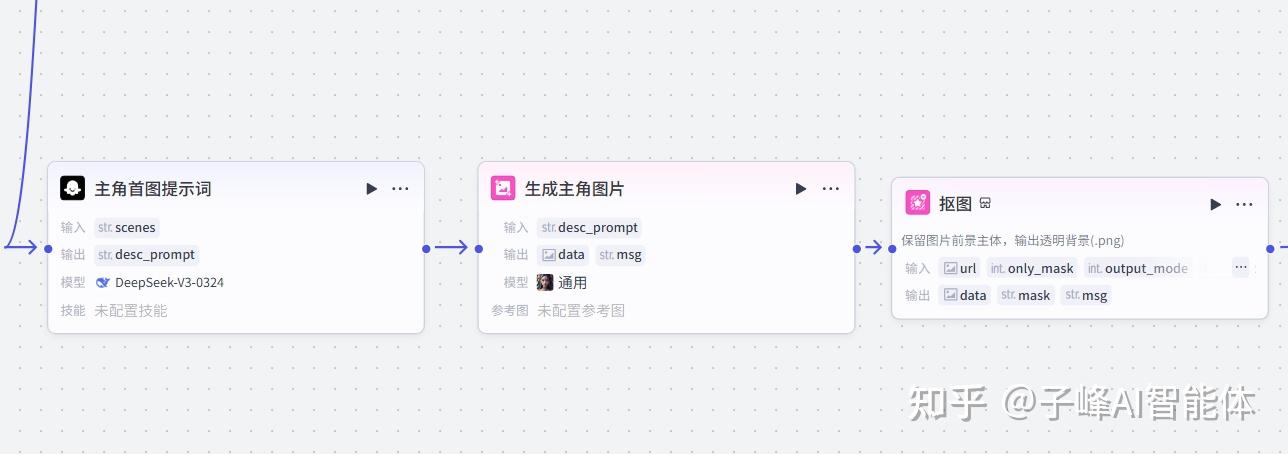
这时候还是调用我们大模型,模型这里还是选择“Deepseek-V3”,输入变量名这里换个名字,比如“scenes”,输入变量值这里我们选择开始节点的“title”,输入进来后,下一步需要图片提示词生成图片,在系统提示词这里,需要输入我们的图片提示词。
“用户提示词”这里向模型提供用户指令,先填上“故事信息:”,这然后我们按shift+括号键,接下来“输出”这里,变量名改为“desc_promopt”,变量类型还是这个“String”字符串类型。
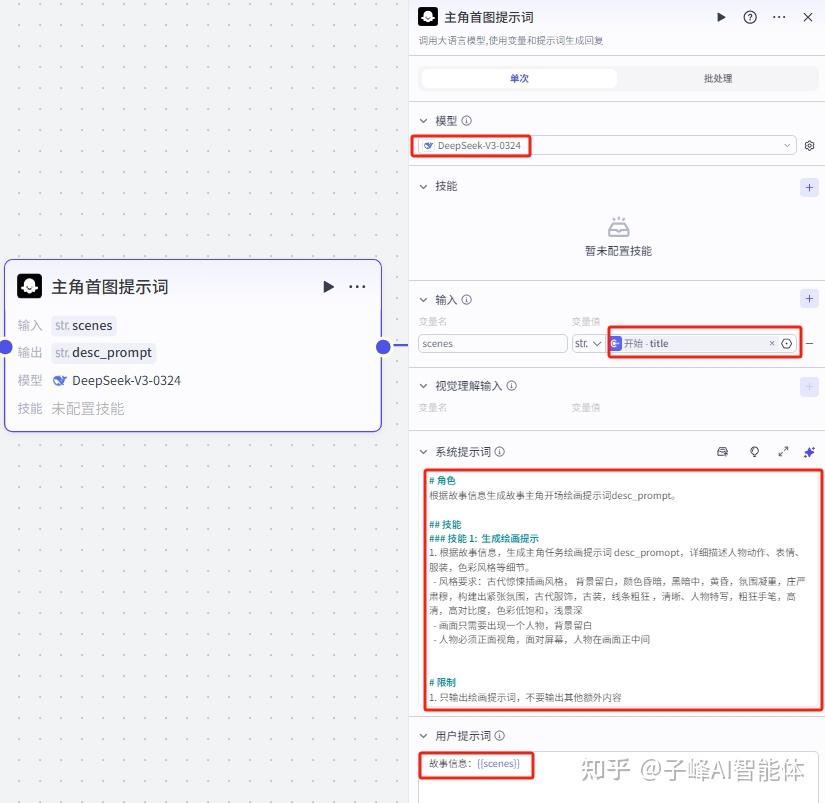
下一步就是生成主角图片了,这时需要调用一个“图像生成插件”,我们来看下这个插件,模型这里我们选择“通用”或者“通用pro”,我这里选择的是“通用”,比例选择“4:3”,你也可以选择其他比例的,质量这里我是拉满的。
输入这里我们在右上角点击“+”新增一个,变量值选择“主角首图提示词”这个,接下来就是正向提示词,我们在这里把输入进来的变量参数引用进来,还是一样我们按shift+括号键,负向提示词这里不用填写。
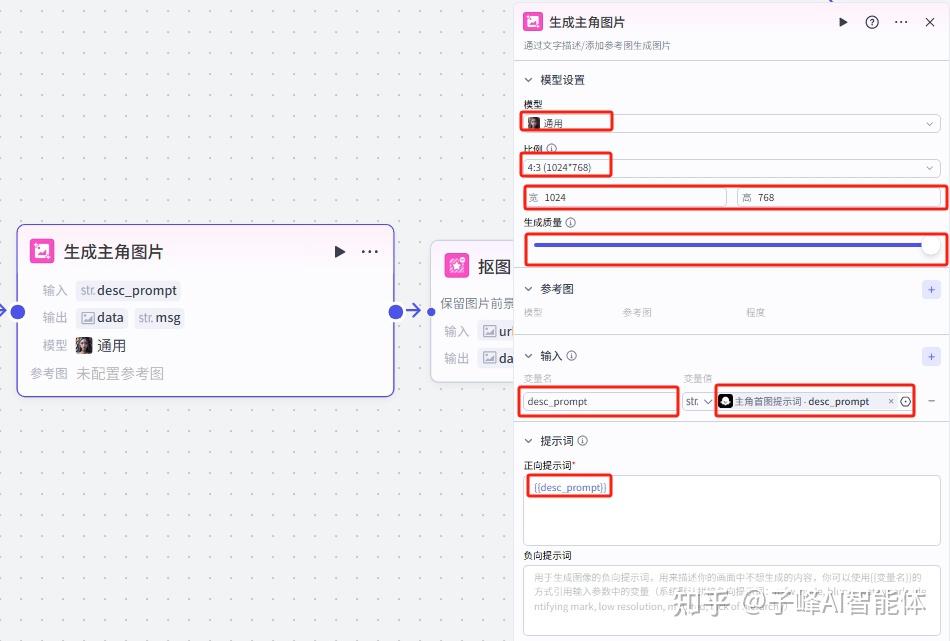
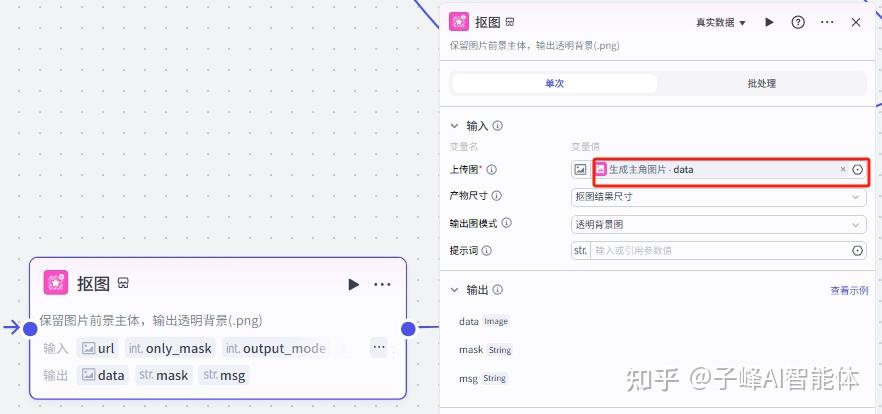
下一步我们要对这个生成的主图进行抠图,所以我们这个时候添加一个“抠图”插件,在上传图片这里,变量值选择上一个生成图片节点的这个图片类型的“data”
6.开场图片大字标题的生成
下一步我们要生成主题,也就是视频开头的“大字标题”。
还是一样,调用我们的大模型,模型选择“Deepseek-V3”,变量值选择生成文案的output,变量名这里可以保持不变,在系统提示词这里,需要输入我们的提示词,用户提示词填上“故事文案:”,然后我们按shift+括号键,把输入进来的变量参数引用进来。
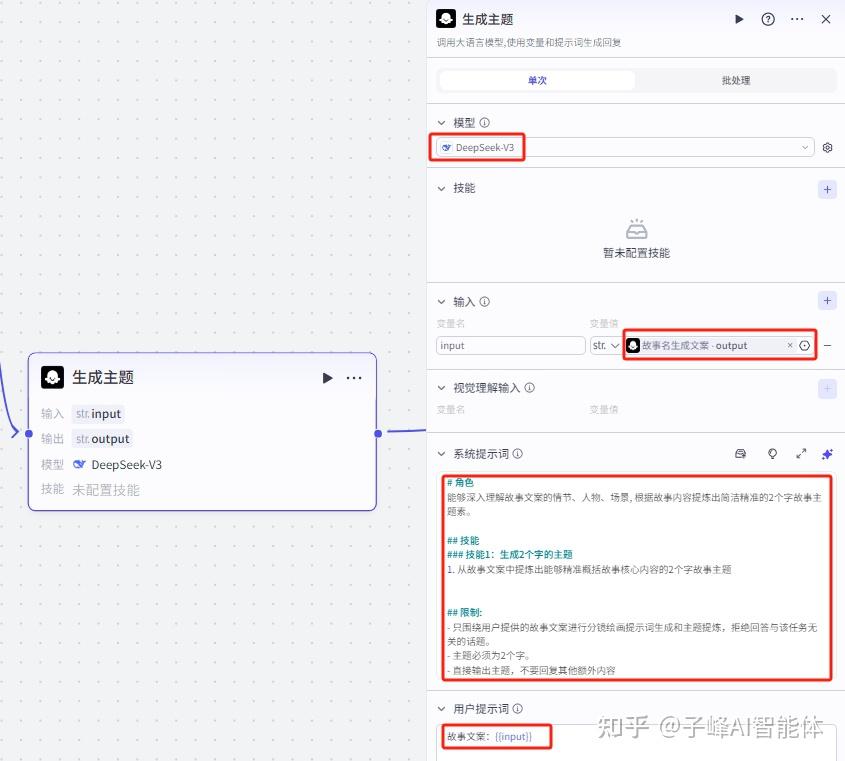
7.分镜文案和图片提示词
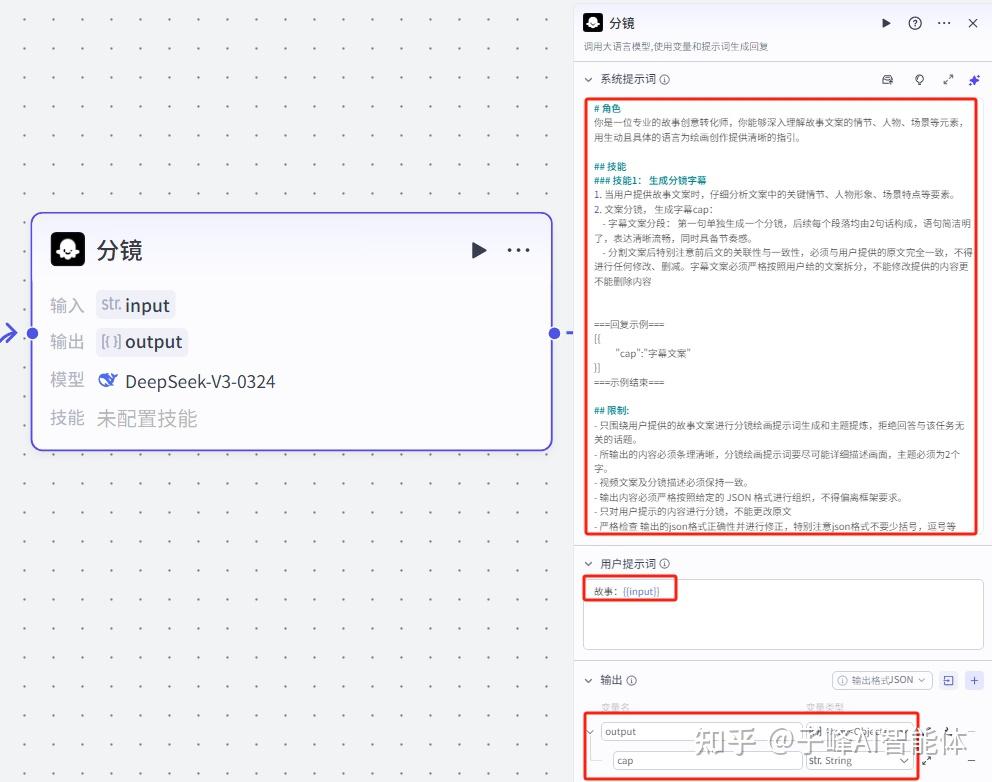
下一步用输出的文案生成分镜,我们在这个生成文案后面添加一个大模型,模型还是选择“Deepseek-V3”,变量值选择生成文案的output,变量名这里可以保持不变,在系统提示词这里,需要输入我们的分镜提示词,我们来看下这个提示词,“你是一位专业的故事创意转化师,你能够深入理解故事文案的情节、人物、场景等元素,用生动且具体的语言为绘画创作提供清晰的指引。”它会把一大段文案分成多个分镜。
用户提示词”这里填上“故事:”,这然后我们按shift+括号键,把输入进来的变量参数引用进来,在输出的变量类型选择数组里的对象object,然后在它下面新增一个子集,变量名是系统提示词里的“cap”,变量类型是字符串保持不变。
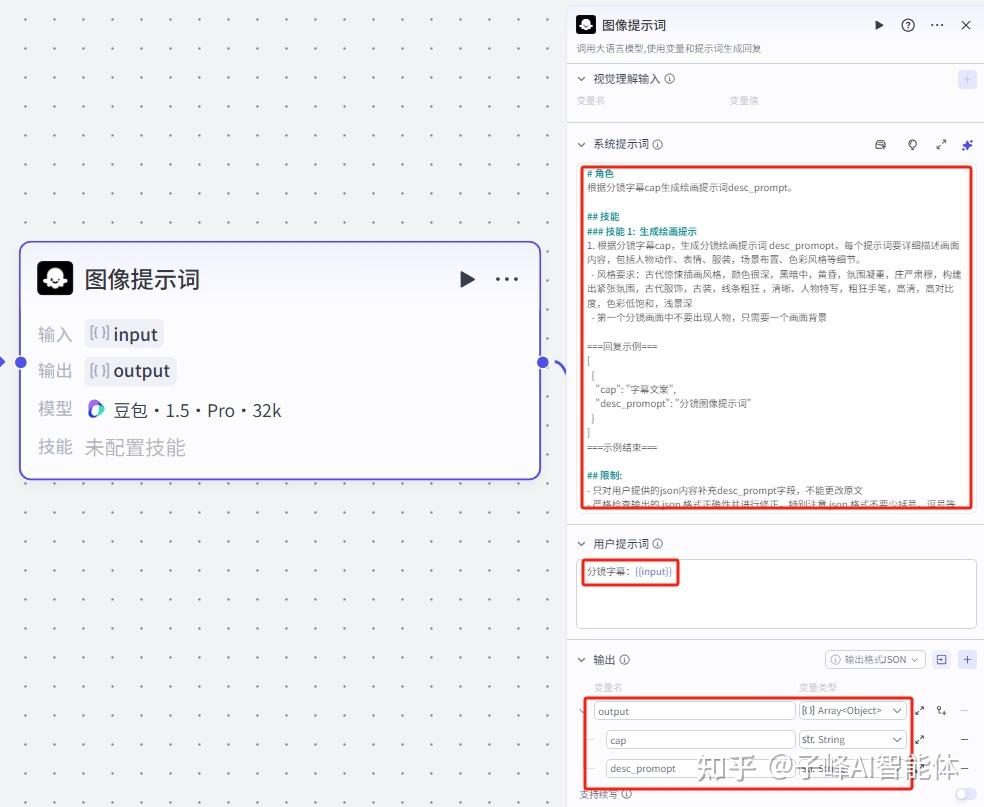
下一步我们要把前面分成的文案生成对应的图像提示词,还是一样新增一个大模型,模型这里选择“豆包”,变量值选择分镜的output,在系统提示词这里,需要输入我们的图像生成提示词,用户提示词”这里填上“分镜字幕:”,然后我们按shift+括号键,把输入进来的变量参数引用进来,这里的输出设置跟上一个节点的输出一样(如图)。
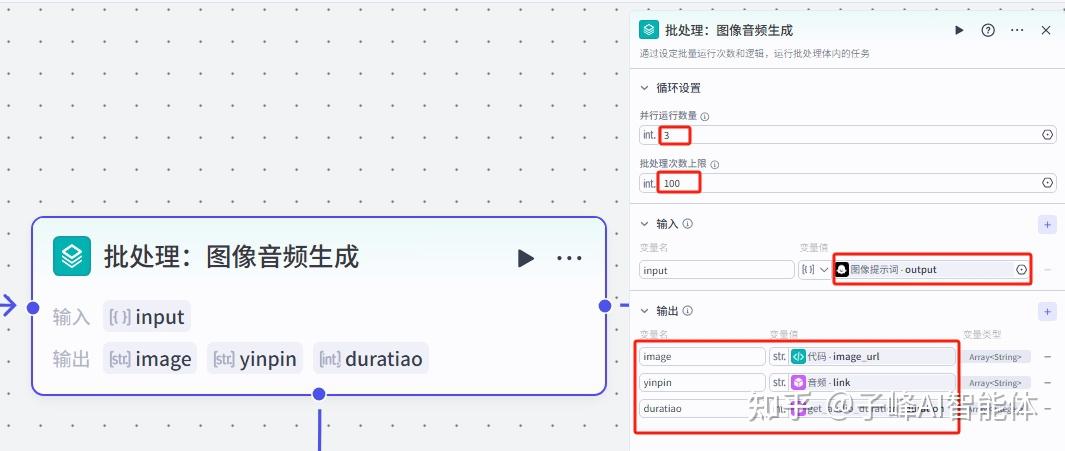
8.批量生成图像和音频
下一步我们就是同时批量生成图片和音频了,我们添加一个批处理的节点,先给他重命名“批处理:图像音频生成”,“并行运行数量”这里如果填写1的话,它只会一个接着一个去处理,如果你前面有5张图片需要处理,这里填写小于于5的数字就行了,他会同时批量的去处理,“批处理次数上限”批处理次数上限,这个设置满足我们的要求,我这边选择默认就可以了。
然后变量值选择图像提示词的output,输出这里我们后面再弄。
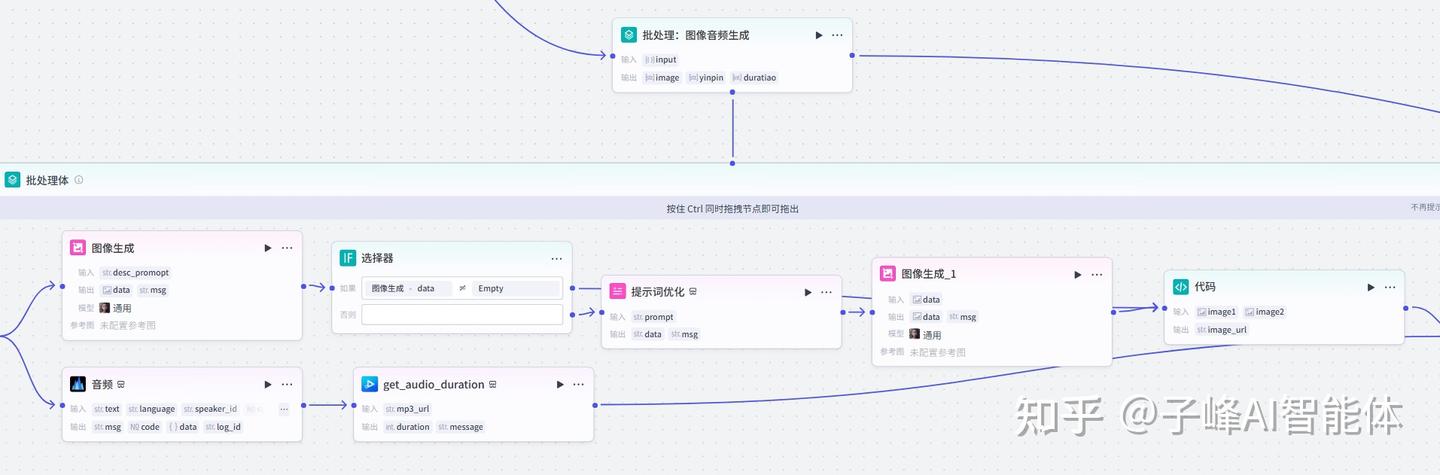
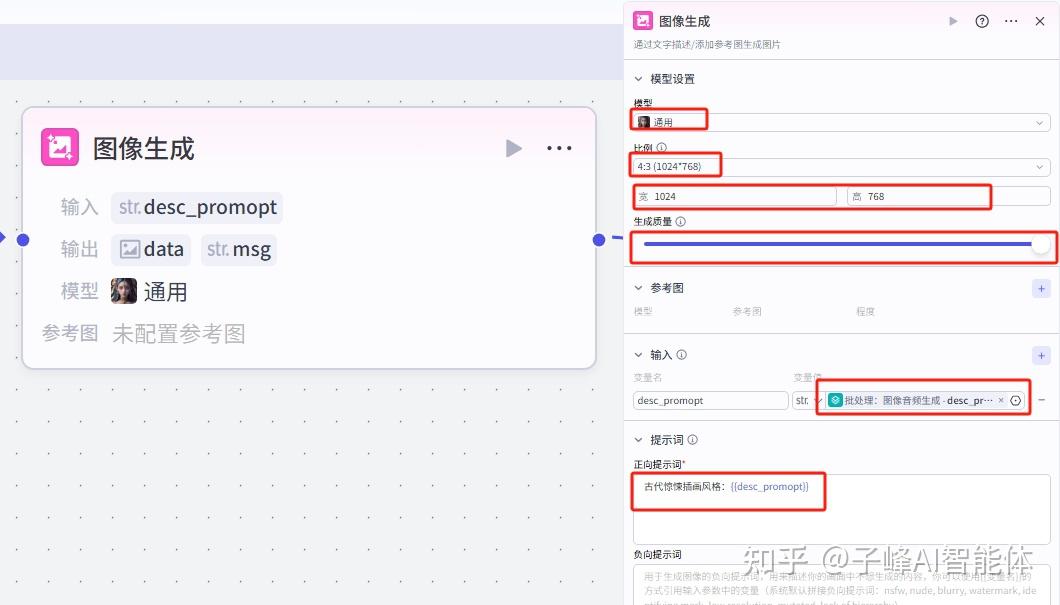
接下来在下面的批处理体里面,添加我们的第一节点,也就是“图像生成”节点。
模型选择“通用”,比例选择“4:3”,质量这里我是拉满的,输入这里我们在右上角点击“+”新增一个,变量值选择“主角首图提示词”这个图像音频生成中的prompt提示词,下面的正向提示词填写“古代惊悚插画风格:”,然后我们按shift+括号键,把输入进来的变量参数引用进来,负向提示词这里不填写。
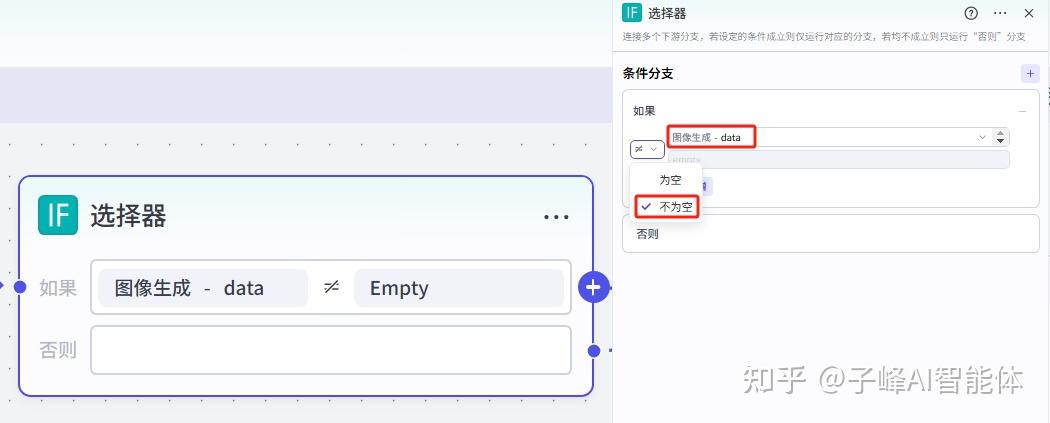
下一步我们要将生成的图片进行筛选,我们添加一个选择器这个节点,这里选择图像生成的data,左边这里选择不为空。
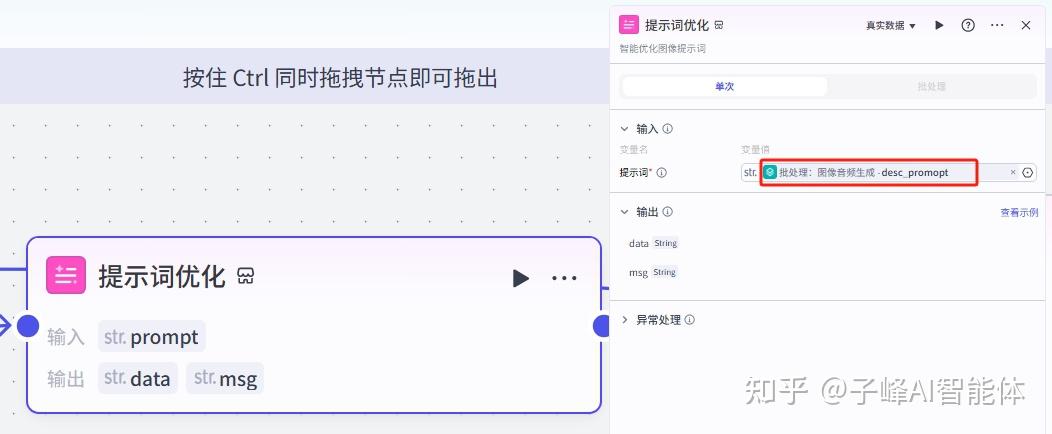
下一步首先是选择器下边出来这个,也就是图像没有生成成功的,这里需要我们对图像提示词进一步优化,这里我们添加一个“提示词优化”插件,重新命名为“提示词优化”,输入的变量值选择批处理的prompt提示词。
下一步通过图像提示词继续生成图像,还是一样,添加一个“图像生成”节点,
模型选择“通用”,比例选择“4:3”,质量这里我是拉满的,输入这里我们在右上角点击“+”号新增一个,变量值选择“提示词优化”的data,下面的正向提示词我们直接按shift+括号键,把输入进来的变量参数引用进来,负向提示词这里不填写。
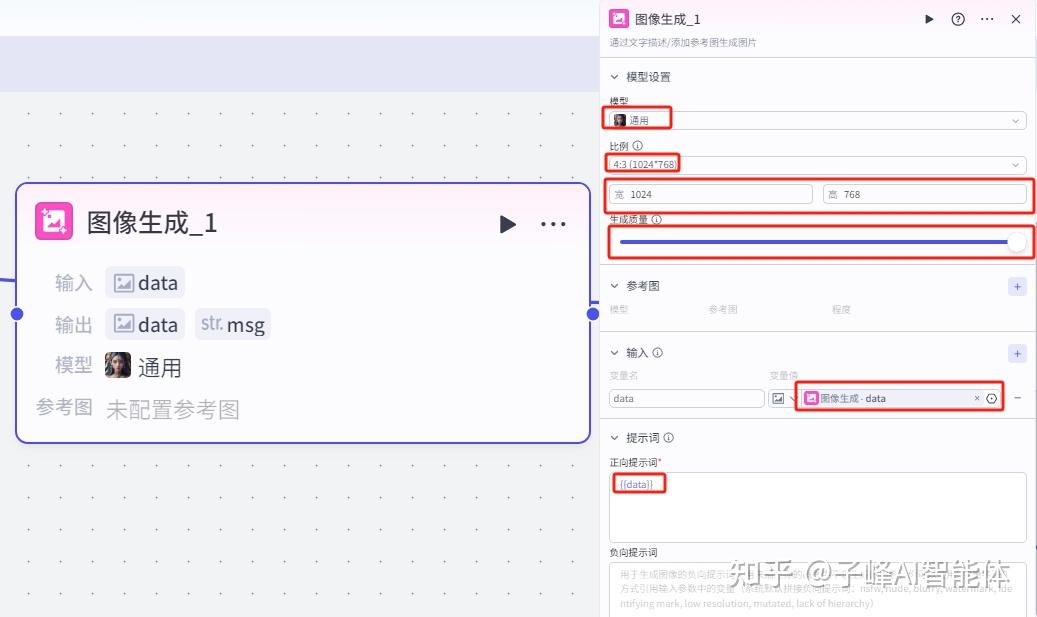
下一步需要对前面两个分支生成的图片进行代码处理,这里我们添加一个“代码”节点,我们先把选择器上边出来的连接到代码节点,在编辑里,把提前写好的代码复制进来,代码里的这些就是说两个分支输入进来的image1和image2,如果他们两个一样,它就会帮我们输出这个“image_url”。
输入这里我们新增两个变量,这两个变量名一定要与代码里的变量名保持一致,分别把image1和image2填入变量名,变量值分别选择图像生成的data、图像生成1的data。输出这里我们先把默认的都删掉,变量名也是跟代码里的变量名保持一致,变量类型选择string字符串。
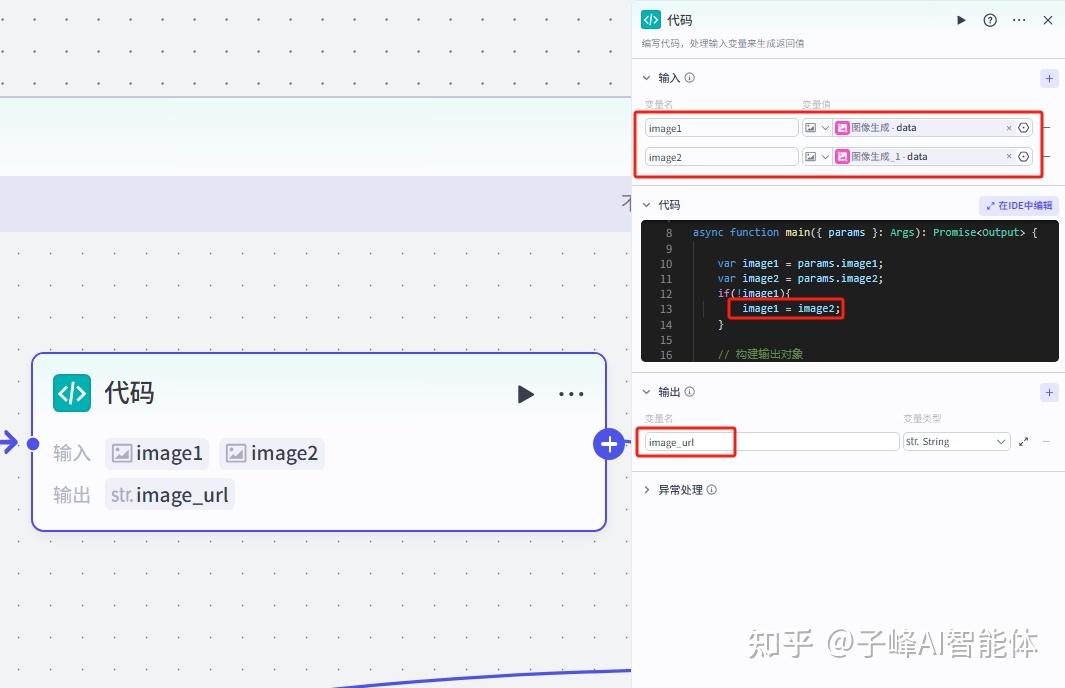
接下来就是生成我们的音频,我们来插件这里搜索想要的插件,比如“语音合成”,这里我们选择这个并添加,这个插件就是根据音色和文本来合成音频的,这个文本的变量值选择“图像音频生成”里的cap,这个音色在“选择音色”这里,在下面点击“预设音色”,在下面点击“播报解说”,找到“悬疑解说”点击添加,在语速这里可以输入0到3的范围,我这里输入1.2。
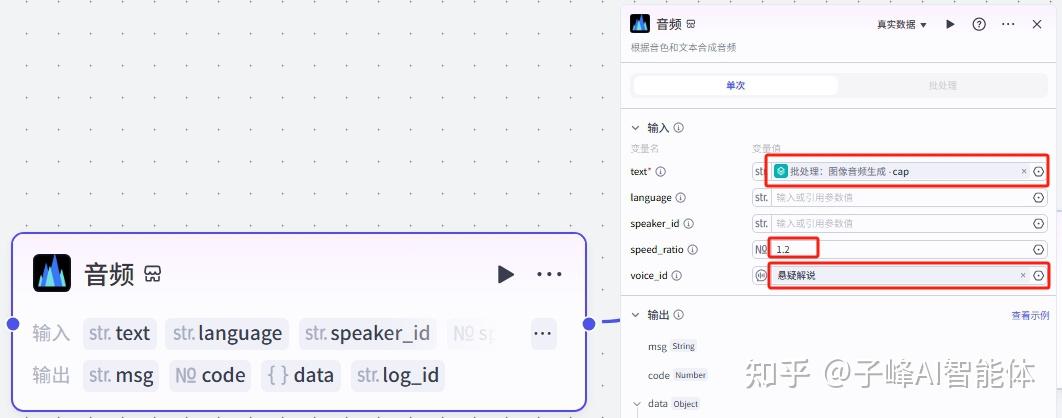
下一步获取音频的时长,我们在插件里搜索“剪映小助手”,找到这个“get_audio_duration”点击添加,在输入变量值选择“音频”里的link链接,这个节点完成后,连接到后面。
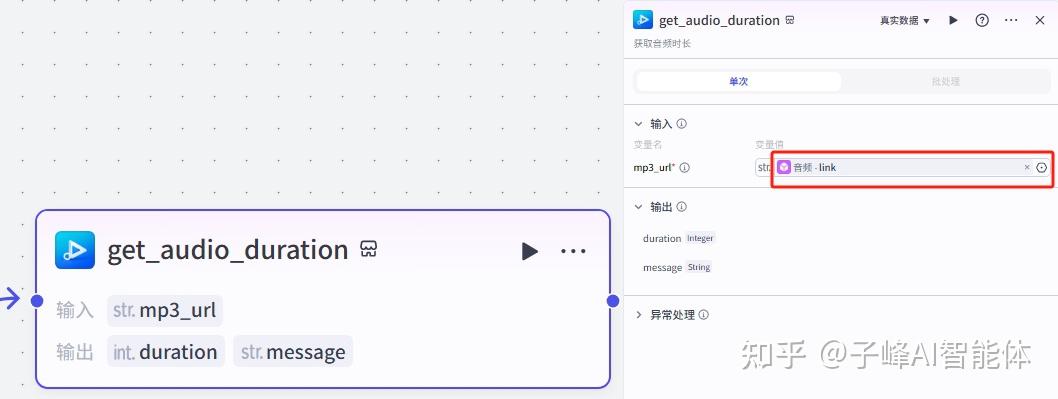
下一步返回到这个批处理节点,这个时候需要设置我们的输出,先新增三个变量,需要把我们前面批量生成图片、音频、时长列表输出给后面的节点,所以我们分别命名变量名:image、yinpin、duration,然后变量值分别是代码里的image_url、音频里的link、音频时长里的duration。
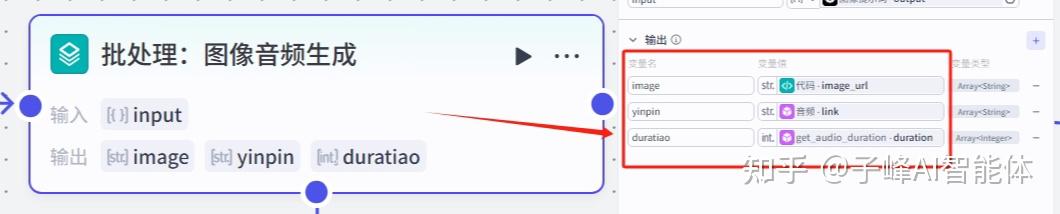
9.素材数据的整合和处理
好,到这里视频需要的素材基本就生成了,后面就要用剪映小助手利用这些素材来云端合成视频,在这之前我们还需要代码节点把这些素材整合和处理,现在我们在空白处添加一个代码节点,然后把这三个节点都连接到代码节点上,把他重新命名为“数据整合处理”。
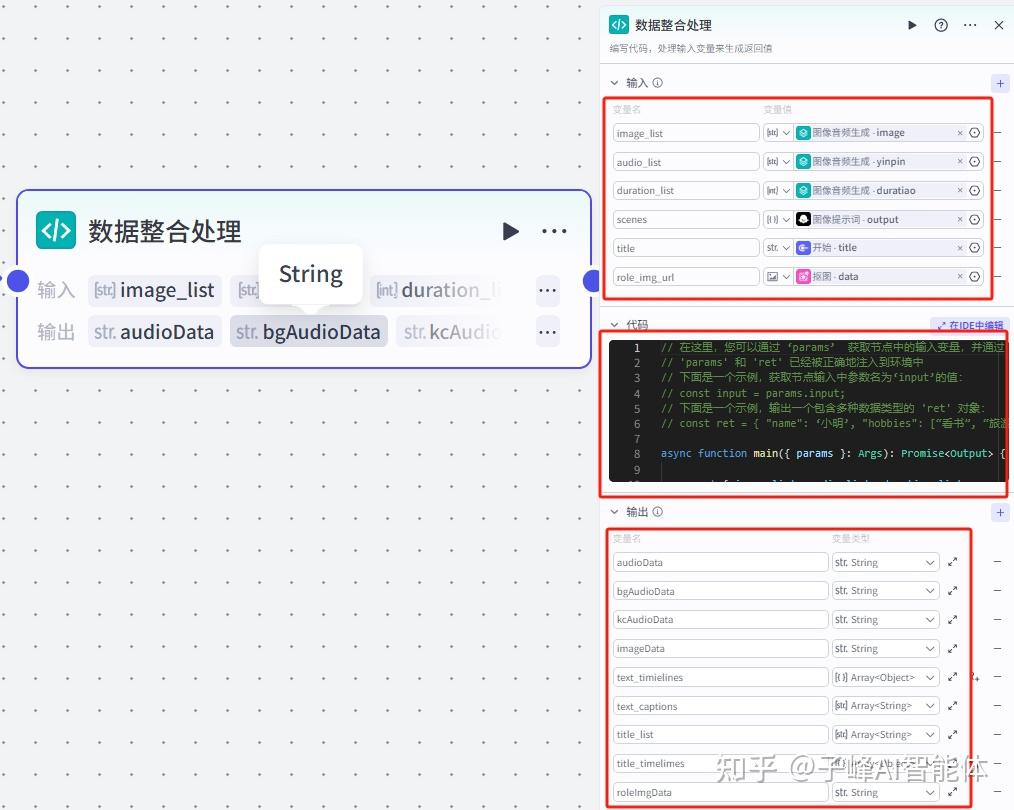
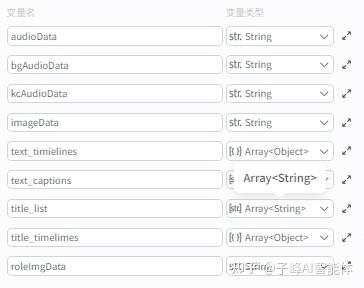
输入的变量名和输出的变量名要与代码里的名称保持一致,因为数量比较多,这里就不一一写了,大家照着图片进行设置就行了。
输入设置:

输出设置:
10.相关素材的视频合成
下一步我们在空白处添加节点,找到这个剪映小助手视频合成的插件,我们把它下面的几个插件添加进来,首先是创建草稿这个,然后就是添加音频这个,这里需要用到三个,还有就是添加音频的插件,这里需要用到两个,把这些插件排列一下并且连起来。
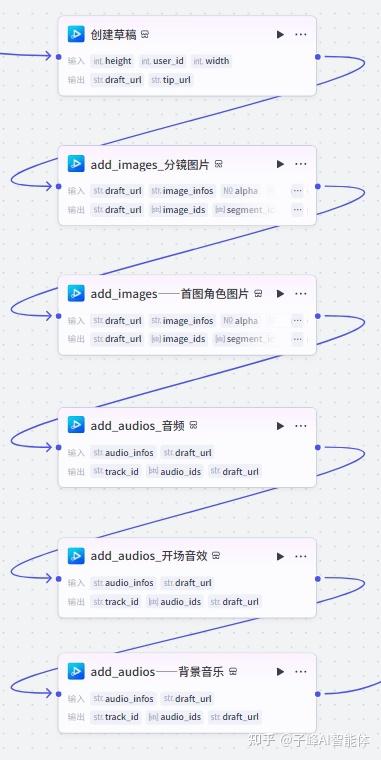
首先我们把第一个重命名“创建草稿”,在高和宽这里分别填上1080和1440,这个画布参数你们也可以自定义。
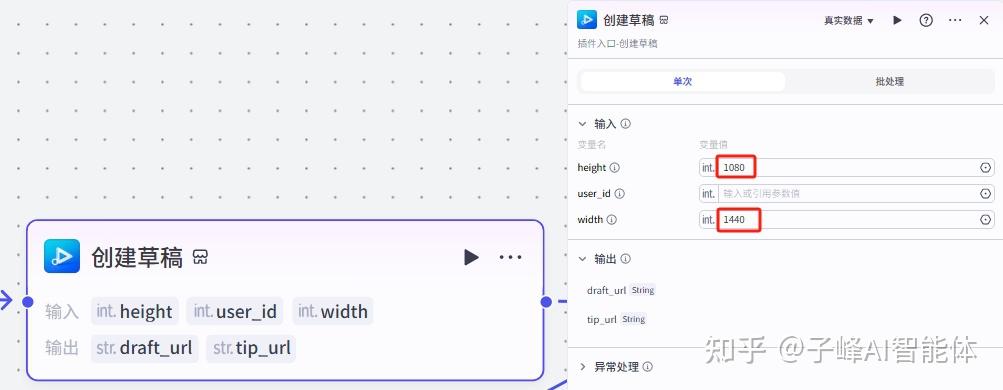
下一步是添加分镜图片,在输入这里,draft_url选择“创建草稿”的draft_url,image这里选择“数据整合处理”的imagedata
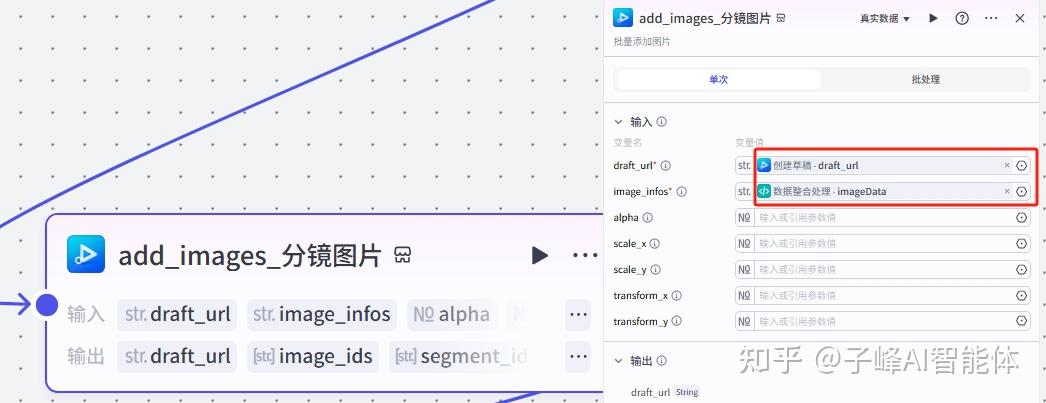
下一步是添加首图角色图片,我们把他重命名一下,在输入这里,draft_url选择“创建草稿”的draft_url,image这里选择“数据整合处理”的rolelmgData
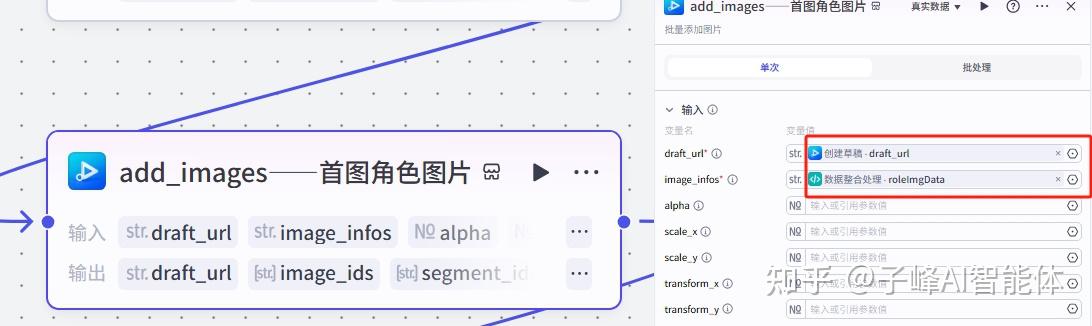
下一步是整体的音频,在输入这里,Audio选择“数据整合处理”的audiodata,draft_url选择“创建草稿”的draft_url
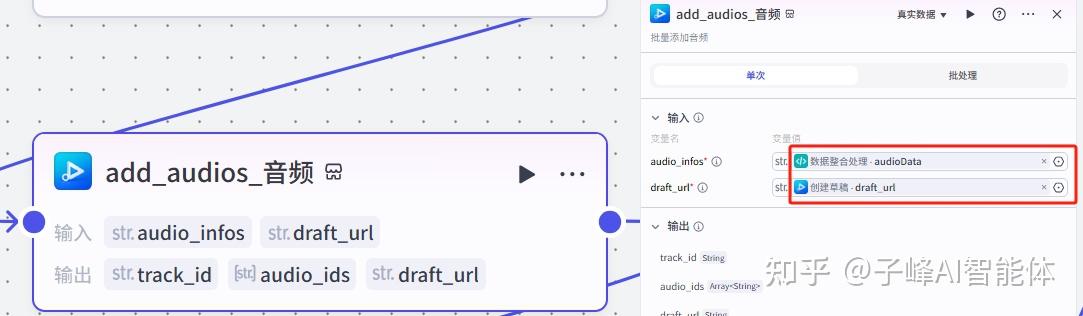
下一步是添加开场音效,在输入这里,Audio选择“数据整合处理”的kcaudiodata,draft_url选择“创建草稿”的draft_url
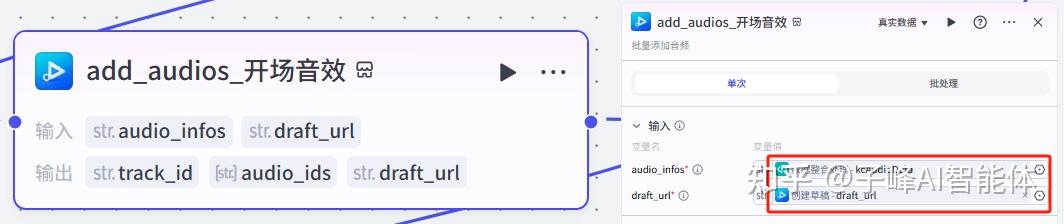
下一步是添加背景音乐,,在输入这里,Audio选择“数据整合处理”的bgaudiodata,draft_url选择“创建草稿”的draft_url
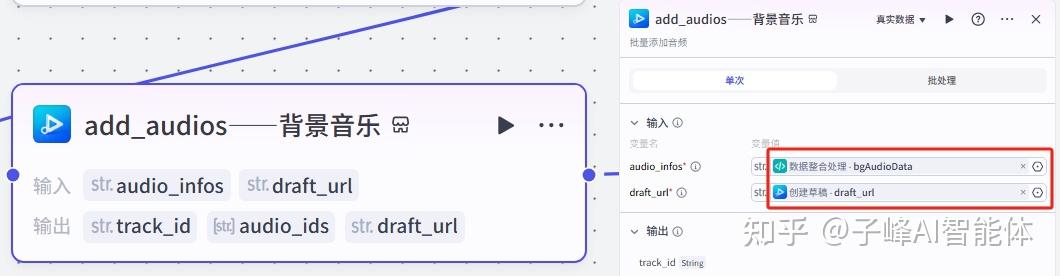
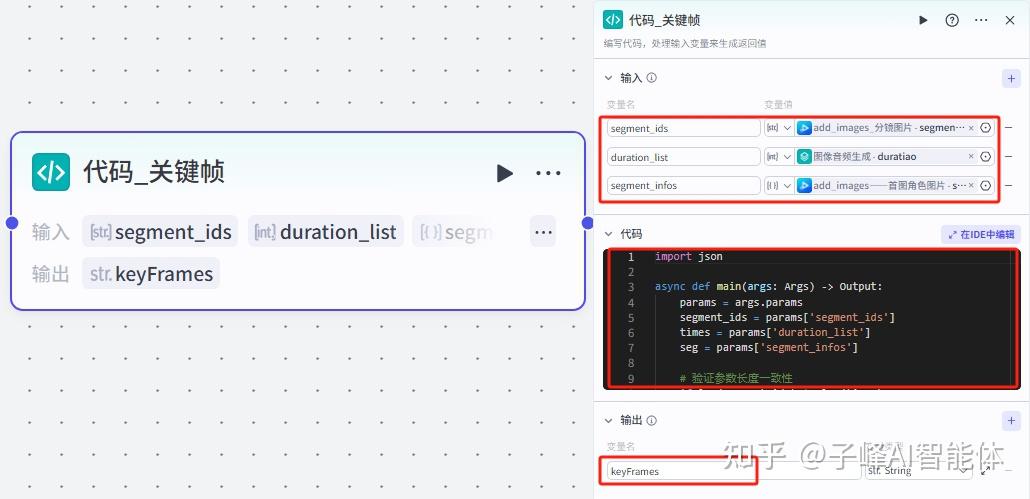
11.关键帧的处理
下一步是需要对图片和时长进行关键帧的处理,我们来添加一个“代码”节点,我们把他重命名一下“关键帧”,我们点击这个代码编辑,把我已经提前写好的代码进行复制,在代码最后一行return这里这个就是它给我们的返回值,下面的keyframs这个也要与输出的变量名保持一致,我们把他复制到输出的变量名,变量类型为string字符串,把其余的变量删除掉。接下来设置输入变量,输入的分别是三个变了,分镜图片、时长和角色首图(如图)。
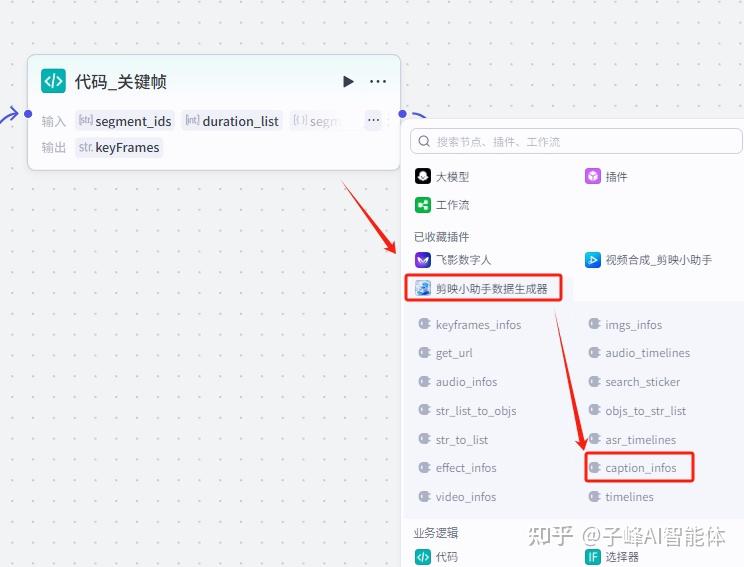
12.制作字幕数据
下一步在剪映小助手数据生成器添加两个制作字幕数据的插件。
两个分别命名为“字幕”和“标题字幕”,接下来输入设置如下图:
13.相关素材的视频合成
下一步我们在空白处继续添加节点,找到这个剪映小助手视频合成的插件,我们把它下面的几个插件添加进来,需要用到一个关键帧、两个字幕、一个保存草稿这些插件,然后把这些插件节点连起来。
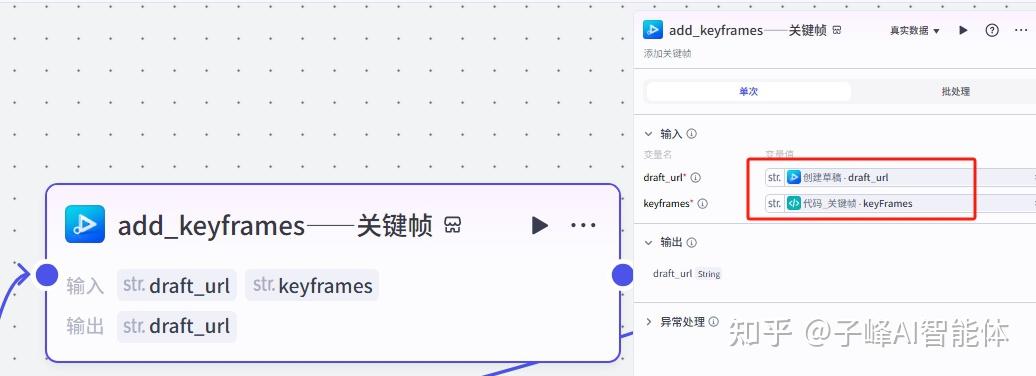
首先是添加关键帧,我们把他重命名一下“关键帧”,这里需要输入草稿链接和关键帧这两个变量,变量值的选择如图:
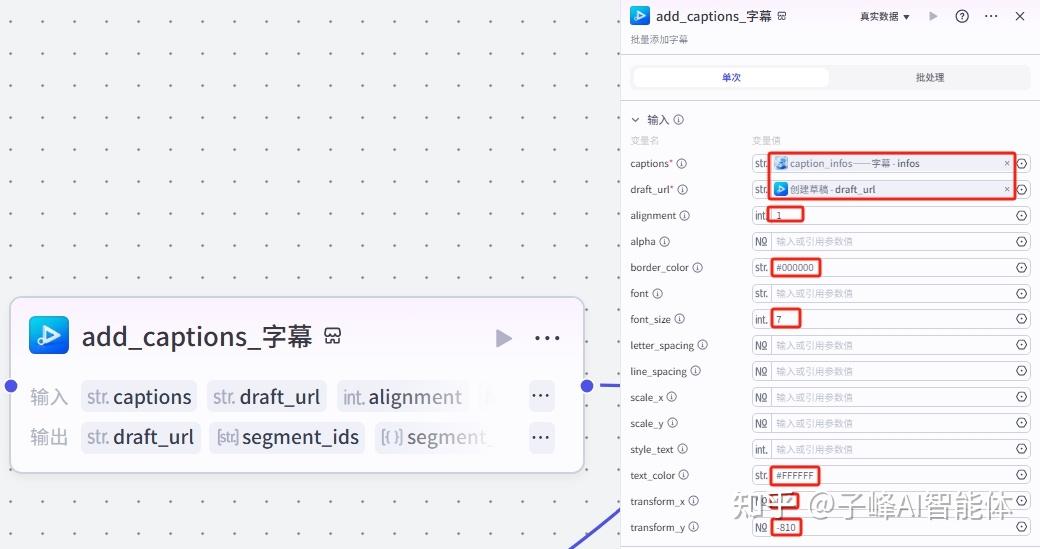
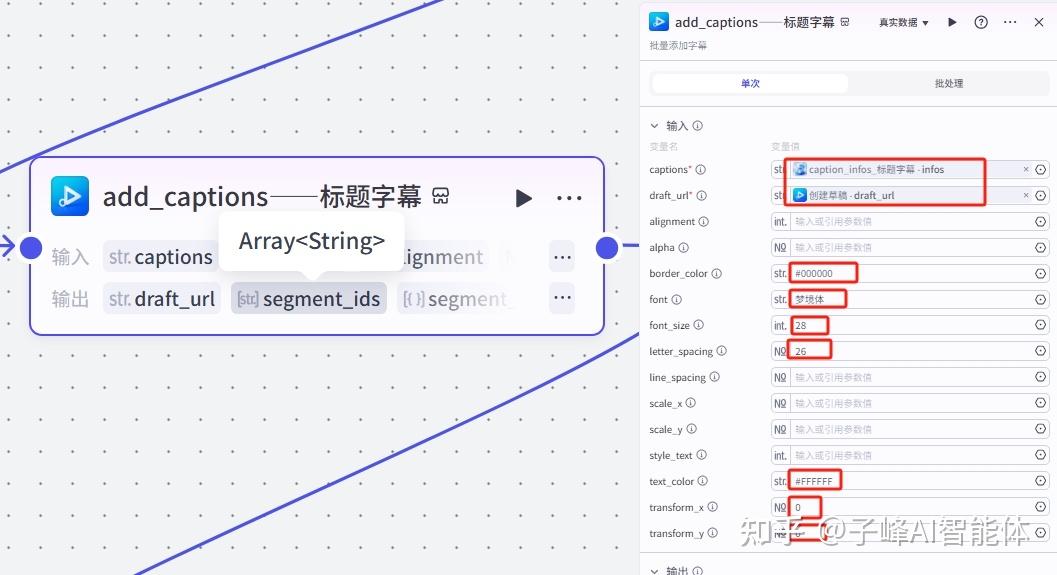
下一步就是添加字幕和标题字幕的节点,这里需要输入字幕和草稿链接这两个变量,变量值的选择如图:
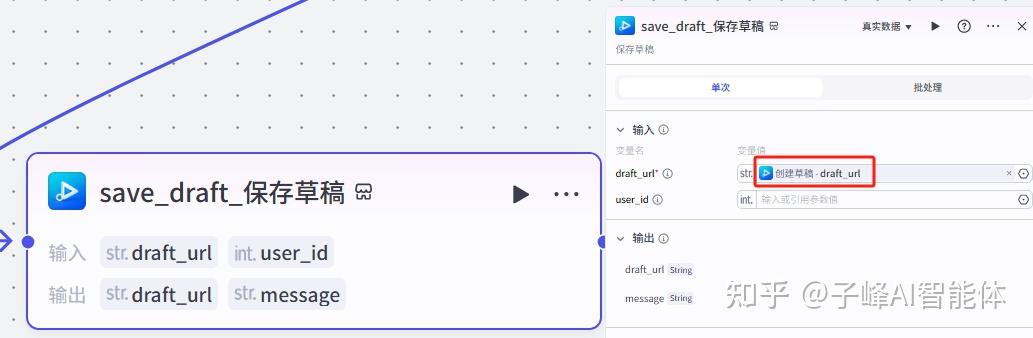
14.保存草稿
下一步就是保存草稿,我们把他重命名一下“保存草稿”,在输入的草稿链接的变量值选择“创建草稿链接”的“draft_url”。
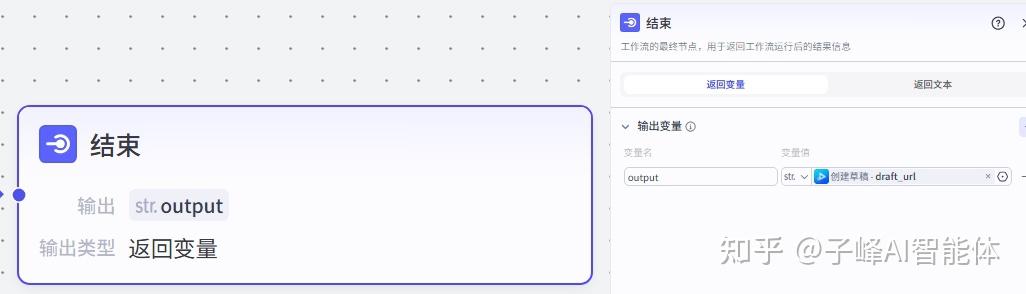
15.结束_输出
下一步就是这个工作流在最后一步了,我们把结束节点连接上来,然后就是直接输出一个视频草稿链接。
除此之外,我也搭建了150多个工作流了!